
A Basic Logger
Game Engine Series · by Frederic Schönberger
Series overview
- How to write a game engine from scratch — In this article, we set up the basic project structure with C++20 modules.
- A Basic Logger — You are here.
- Rendering Overview — Here, we discuss rendering, define high-level and low-level rendering and sketch what we're about to build.
- First steps with Vulkan — In this part of the series we create the Rendering Subsystem and initialize a Vulkan Instance.
- Vulkan Validation Layers — In this article we’re going to enable validation layers for our Vulkan renderer. They allow us to catch commong mistakes and errors in Vulkan code.
In this part of the Voxel Game Series we’re going to talk about logging. Logging is a vital part of any software project, and the same is true for a game engine. Logging allows you to quickly check the state of your systems, trace variables and more.
A quick history of logging
Logging exists as long as programming does[citation needed]. It just means to print some programmer-defined strings whenever a certain event happens:
void foo() {
std::cout << "Doing foo()";
try {
bar();
std::cout << "bar() succeeded!\n";
} catch(const std::exception& e) {
std::cerr << "bar() messed up, the error is " << e.what() << "\n";
} catch(...) {
std::cerr << "bar() messed up, no idea what the error is\n";
}
std::cout << "Done with foo()\n";
}We can see that the programmer wants to see what’s happening inside foo(). In the “normal” case output goes to cout, in case of an error to
cerr.
Programmers quickly realized that while “printf-debugging” is a good idea (especially to figure out why your program crashed on someone else’s computer), it could benefit from some more structure. There are some pieces of information that are almost always important:
-
The severity of the message: Is it fatal, just an error, merely a warning, some piece of info or very specific debug information?
Commonly fatal is defined as an error that needs the program to abort when occuring (e.g., a
SEGFAULT). An error may be handled by first cleaning up (closing file handles, …) and then terminating the program. Warnings can be remediated by calling code or sometimes even ignored. Info is just for the programmer. Finally, debug is just for debugging purposes and shouldn’t be present in release builds. -
When did the log message occur? Timestamps, ideally with timezone.
-
Where did the log message occur? This often includes the process id, thread id, calling function, name of the source file and line in the source file.
-
Sometimes we want to group or tag log messages. Common queries would be “All networking messages”, “what did the Event Manager do?”, and so on. This is where channels come in.
There are many logging libraries for different languages out there. log4j2 ,
logback and serilog are widely known and used. Chances are, the programming language of your choice
already has one or more logging facilities…
… except for C++, because the standard library really doesn’t have much.
As a side note: Due to the abundance of logging libraries and frameworks one common pattern programming languages use is to use a logging facade. The
idea is to provide a common API that pipes log message through to the actual implementation. Examples would be SLF4J ,
Apache Commons Logging , Castle Windsor’s Logging
Facility or Rust’s log crate . It
is considered best practice for libraries to just use Logging Facades so the consuming application can choose an appropriate implementation.
At the time of writing, C++ doesn’t have a standard logging facade.
Choosing a logging library
While we could implement a simple logger ourselves, it’s tedious work and other people have probably done a better job anyways. So let’s see how we could find a library that fits our use case.
As true programmers the first thing we do is ask reddit . The library should be able to handle being embedded in a shared library 1 . It ideally should be compatible to existing frameworks, such that external tools like Apache Chainsaw 2 or Logbert can be used.
The top answer spdlog was really annoying to use in combination with shared libraries. Since we’re going to be using boost anyway, we will just go
ahead and choose Boost.log.
Getting started with Boost.Log v2
When your first look at Boost.Log v2’s Documentation , it’s a lot. Let’s summarize the main concepts. If this summary is too short for you or you want more detail, have a look at the Design Overview .
Quoting my sources
Most of the ideas in the following section are not my own. Instead, I rely heavily on the aforementioned Design Overview .
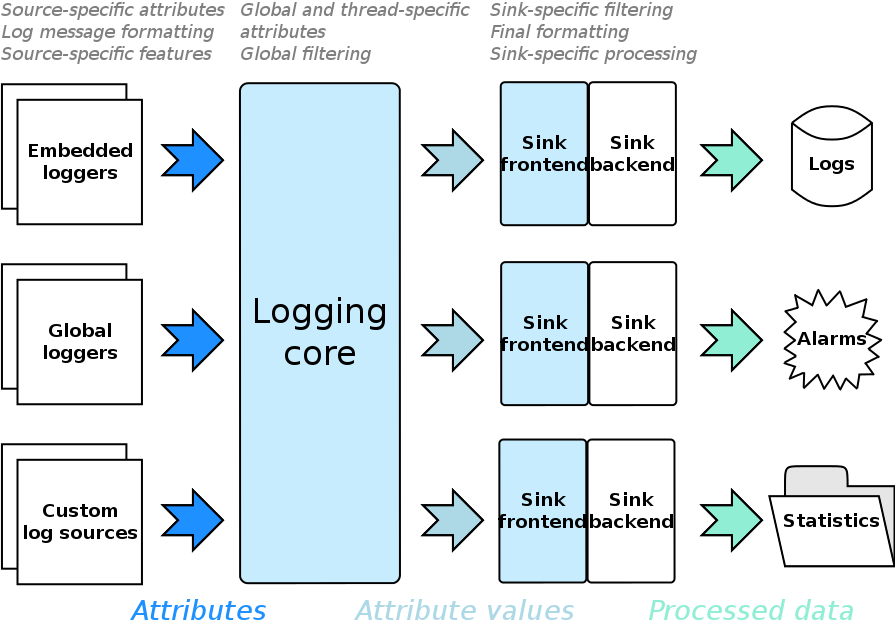
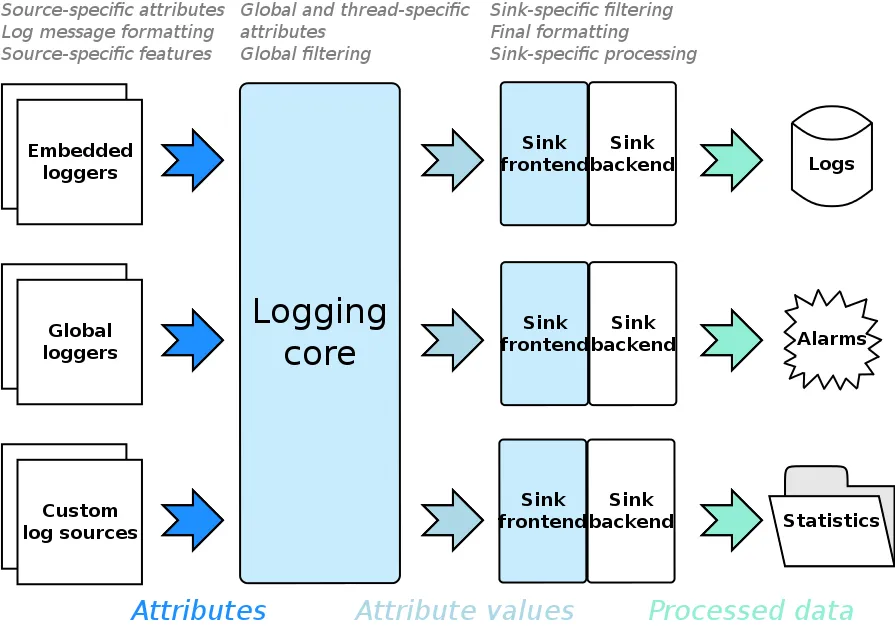
There are log sources. Log sources are entities that initiate logging by constructing a log record. Most of the time a log source is a logger.
Of course, you can develop own log sources (maybe to trace network traffic, capture a child application’s stderr, …), but for the moment, think of
log sources just as either global or embedded (owned by a class) loggers. In fact, for the remainder of the text I’m going to just call it logger.
Loggers pass on data that is associated with a log record to the logging core. We call all data associated with a log record attributes. Or, to be
more precise: Attributes are a means of getting this data, the attribute values. Think of an attribute like a function, and attribute values like
the function’s evaluation. For example, there could be an attribute timestamp with an attribute value of 2022-08-01 12:35:22.
Attributes are scoped into attribute sets: Global, thread-specific and source-specific. While the former two are self-explanatory, we should mention that source-specific attributes depend on the logger. Attributes with the same name are chosen on a priority-basis (global < thread < source). Furthermore, attributes can also be appended on a per-record basis.
This maps naturally to concepts inside our logging system:
- Global attributes should apply to everything (“all records need a timestamp”, “all records should have a counter”).
- Per-thread attributes can give information on the current thread of execution.
- Per-logger attributes can give information on e.g. subsystems (“We have a ‘Audio’ and a ‘Renderer’ logger”).
- Per-record attributes have information on this specific log record, for example the source location.
Aren't attributes structured logging?
When reading about attributes, one might be reminded of structured logging . Structured logging means not logging strings, but instead machine-readable payloads. These can then later be consumed by data analytics tools and can be used to gain valuable insights into your users.
We will later discuss (in theory) how custom log sinks can be used for that purpose.
The logging core takes log records from the loggers, evaluates their attributes and begins to filter them. Examples of global filtering would include severity based filtering, or muting certain channels. Each record that survived the first filtering phase is filtered again, this time on a per-sink basis. Some attributes are only ever attached after filtering and can thus not be used while filtering.
So what exactly are sinks? Sinks take log records and store them somewhere. They might save them to a file, print them to cout, send them over the
network to ElasticSearch or just plain do nothing. Sinks can be formatting sinks. Formatting is the process of transforming a log record to
something else, like a DB record or a string.
Sinks consist of a frontend and a backend. Many frontends are provided by
Boost.Log and take on common tasks like synchronization,
filtering and formatting. A user can implement their own, but it’s not a common need. Backends should be implemented by the user and contain the logic
of actually dealing with the log messages. Boost.Log provides many
backends , for example text files, text streams (like
cout), (remote) syslog and Windows debugger.
Consuming the library
As mentioned in part 1, we’re going to use a package manager for our external libraries. We need to tell it which dependencies our program has. We do
this in the manifest file . NPM users might understand it as a package.json. In this file
we simply declare the dependencies and their versions.
To actually use such a file, add a new text document called vcpkg.json as a solution item. It should be placed in the src/ directory. Here are its
contents:
{
"$schema": "https://raw.githubusercontent.com/microsoft/vcpkg/master/scripts/vcpkg.schema.json",
"name": "voxel-game",
"version-string": "alpha",
"dependencies": [
"boost-log"
],
"builtin-baseline": "e07c62d05970d7d89e336bdb278b02242e8bda7c"
}This pulls in Boost as a dependency with at least version 1.81.0, the newest one at the time of writing. In the proposed setup boost libraries are
linked as shared libraries.
Boost.Log can be either linked as a static or as a shared library. It is required that Boost.Log is linked as a shared library here, otherwise this code won’t work (you can’t access the logger from sandbox). See this StackOverflow answer for more information.
Gotcha! Boost.Log's core and its implementations
Internally, Boost.Log has many implementations for the logging core. They live in separate namespaces. The pattern is
<version><linkage>_<threading>_<system>. Version is always v2. Linkage is either “s” for static or empty for dynamic. Threading is either “st”
or “mt”. Finally, system specifies the target platform and configuration. Valid values are posix, nt5, nt6, or nt62. Examples would be
v2s_st or v2_mt_posix.
When consuming the library by including the headers we need to make sure that our client library uses the same <system> that vcpkg used. Right
now, it just works, but if you encounter errors this might be a source. It apparently is common enough to warrant its own FAQ entry in the
docs .
The goal: a clean logging API
Let’s start from how we want users to use the logging framework:
import engine.log;
int main() {
engine::log_info("Starting engine v{}.{}", 0, 1);
engine::log_warning("Something looks off: {}", "low memory");
engine::log_error("Failed to load {}", "config.toml");
}We don’t want clients to ever think about the implementation of the logging. Yes, we have decided on Boost.Log. In the future, we might want
to update the implementation to Boost2.Log, and don’t want the client to ever worry about this. We also want the source file, line, and function
to be captured automatically. Let’s work backwards from this goal.
The naive attempt: Variadic templates
The obvious first try uses a variadic function template with std::format for string
formatting and std::source_location to automatically capture the call site:
template<typename... Ts>
void log_info(std::format_string<Ts...> fmt, Ts&&... ts,
const std::source_location loc = std::source_location::current())
{
_log(LogLevel::info, std::format(fmt, std::forward<Ts>(ts)...), loc);
}Unfortunately, this doesn’t work: Because loc has a default value, the compiler can’t tell if std::source_location is part of Ts... or not.
You’d have to call log_info<int, float>("{}, {}", 1, 2.f) with explicit template arguments every time, which defeats the purpose.
Class Template Argument Deduction (CTAD) to the rescue
The fix uses Class Template Argument Deduction
(CTAD) . CTAD was introduced in C++17 and lets the compiler deduce
template arguments for class templates from their constructor arguments (similar to how it already works for function templates). A familiar example
is std::pair p{1, 3.14} instead of std::pair<int, double> p{1, 3.14}.
Our clever trick is to turn log_info into a struct and put the actual call in its constructor. Then we add deduction guides to tell the compiler
which constructor arguments correspond to which template parameters:
export template <typename... Ts>
struct log_info {
inline log_info(std::format_string<Ts...> fmt, Ts&&... ts,
const std::source_location& loc = std::source_location::current())
{
::engine::_log(LogLevel::info, std::format(fmt, std::forward<Ts>(ts)...), loc);
}
};
export template <typename... Ts>
log_info(std::format_string<Ts...>, Ts&&...) -> log_info<Ts...>;The deduction guide tells the compiler: “When you see log_info("foo={}", 42), deduce Ts... from the format string and the arguments. Ignore
loc, because it’s not part of the pack.” Now engine::log_info("value={}", 42) just works.
We define the same pattern for log_trace, log_debug, log_warning, log_error, and log_fatal.
Actually logging: _log()
You can see that all of these helpers delegate the actual logging to _log. The function is not exported from the module interface, and serves
as an abstraction layer to Boost.Log.
export enum class LogLevel : int {
trace = 0,
debug = 1,
info = 2,
warning = 3,
error = 4,
fatal = 5,
none = 100 // Higher than any level - mutes a channel completely
};
void _log(LogLevel level, std::string_view message, const std::source_location& loc);Setting up the Boost.Log backend
The CTAD structs and _log define the interface. But how is _log actually defined? We know for sure that it needs a logger, and that logger
needs a sink and a formatter. All of this lives in logger.cpp.
A global logger as an implementation detail of _log
_log needs a Boost.Log logger to write to. We use BOOST_LOG_GLOBAL_LOGGER to create one. This is Boost’s recommended mechanism for a
process-wide logger. Under the hood it’s a singleton: thread-safe, initialized on first access, and unique even across DLL boundaries. The
important thing is that this logger is purely an implementation detail. It lives in logger.cpp and no client code ever sees it.
using ChannelLogger = boost::log::sources::severity_channel_logger_mt<LogLevel, std::string>;
BOOST_LOG_ATTRIBUTE_KEYWORD(severity, "Severity", LogLevel)
BOOST_LOG_ATTRIBUTE_KEYWORD(channel, "Channel", std::string)
BOOST_LOG_GLOBAL_LOGGER(gLogger, ChannelLogger)We use severity_channel_logger_mt which supports both severity levels and channels, and is thread-safe (the _mt suffix).
The two BOOST_LOG_ATTRIBUTE_KEYWORD lines define attribute keywords — named placeholders that we use in formatter and filter expressions. Boost.Log
ships a built-in boost::log::trivial::severity keyword, but that one is hardcoded to Boost’s own severity_level enum. Since we use our own
LogLevel, we define our own keywords that match.
The BOOST_LOG_GLOBAL_LOGGER_INIT macro defines the initialization callback. This is where we set up the logging core: sinks, formatters, and
attributes:
BOOST_LOG_GLOBAL_LOGGER_INIT(gLogger, ChannelLogger)
{
ChannelLogger lg(boost::log::keywords::channel = "General");
boost::log::register_simple_formatter_factory<LogLevel, char>("Severity");We create a logger with the default channel “General” and register a formatter factory. Next, the console sink:
const auto backend = boost::make_shared<boost::log::sinks::text_ostream_backend>();
backend->add_stream(boost::shared_ptr<std::ostream>(&std::clog, boost::null_deleter()));
#ifndef _DEBUG
using console_sink_t = boost::log::sinks::asynchronous_sink<
boost::log::sinks::text_ostream_backend>;
#else
using console_sink_t = boost::log::sinks::synchronous_sink<
boost::log::sinks::text_ostream_backend>;
#endif
const boost::shared_ptr<console_sink_t> console_sink { new console_sink_t(backend) };In debug builds, we use a synchronous sink so log messages appear immediately (useful when debugging crashes). In release builds, we use an asynchronous sink with an unbounded FIFO queue (the default). This offloads the actual I/O to a background thread so logging never blocks the calling thread.
Boost.Log offers several queue strategies for asynchronous sinks. There are two axes of choice:
- Bounded vs. unbounded: Bounded queues (e.g.
bounded_fifo_queue<8192, block_on_overflow>) apply backpressure when the queue is full — either blocking the producer or dropping records. We chose unbounded because blocking on a log call in a render loop would be far worse than a temporarily large queue, and if we’re producing log messages faster than they can be written tostd::clog, we have bigger problems than memory usage. - FIFO vs. ordering: In a multithreaded application, log records from different threads can arrive at the queue slightly out of chronological order. FIFO queues process records in arrival order, which is usually good enough. Ordering queues sort records by an attribute (like a timestamp or sequence number) before passing them to the backend, at the cost of a small added latency. We use FIFO because slightly out-of-order console output is a non-issue for us, and the ordering overhead isn’t worth it.
Formatters with color support
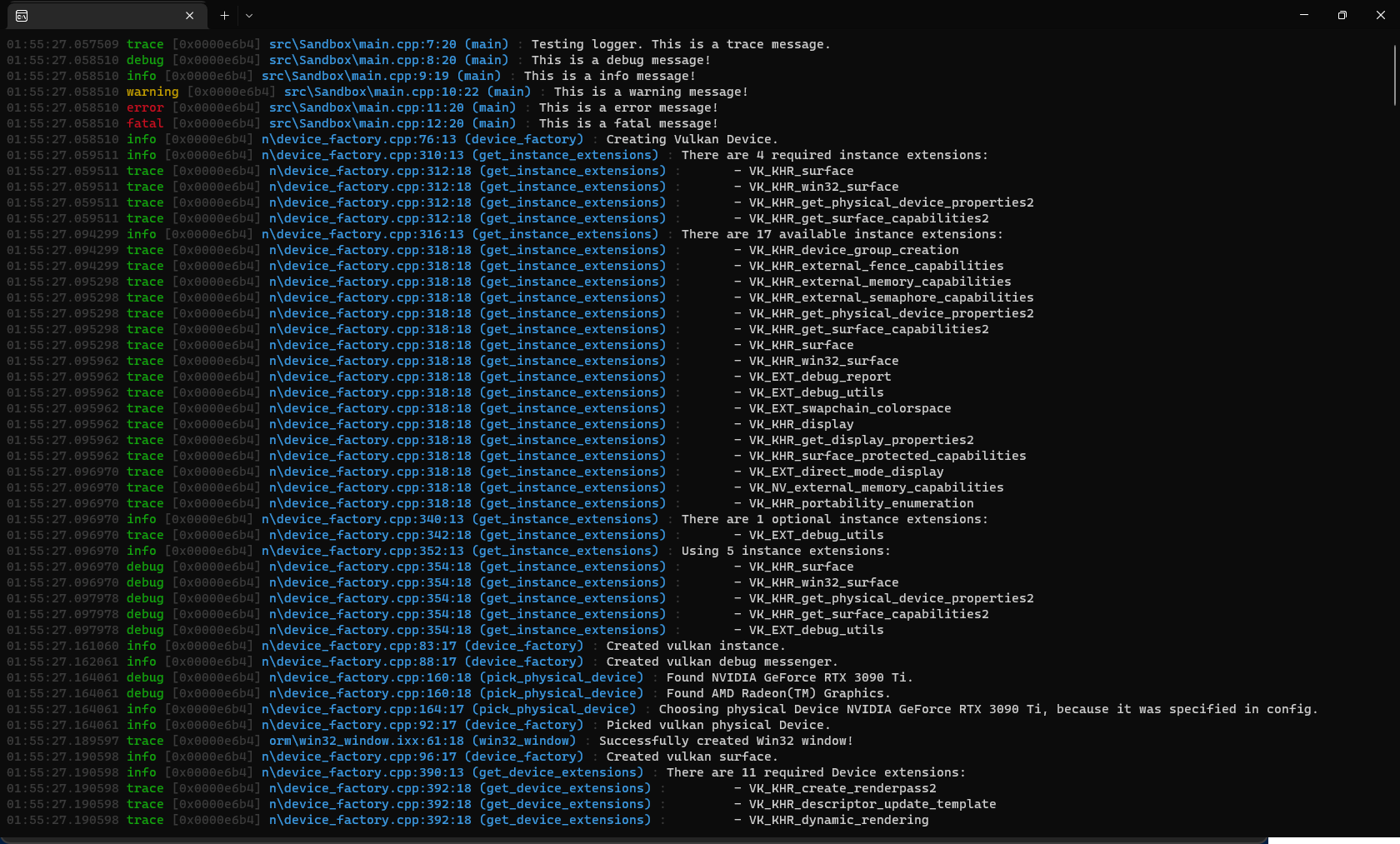
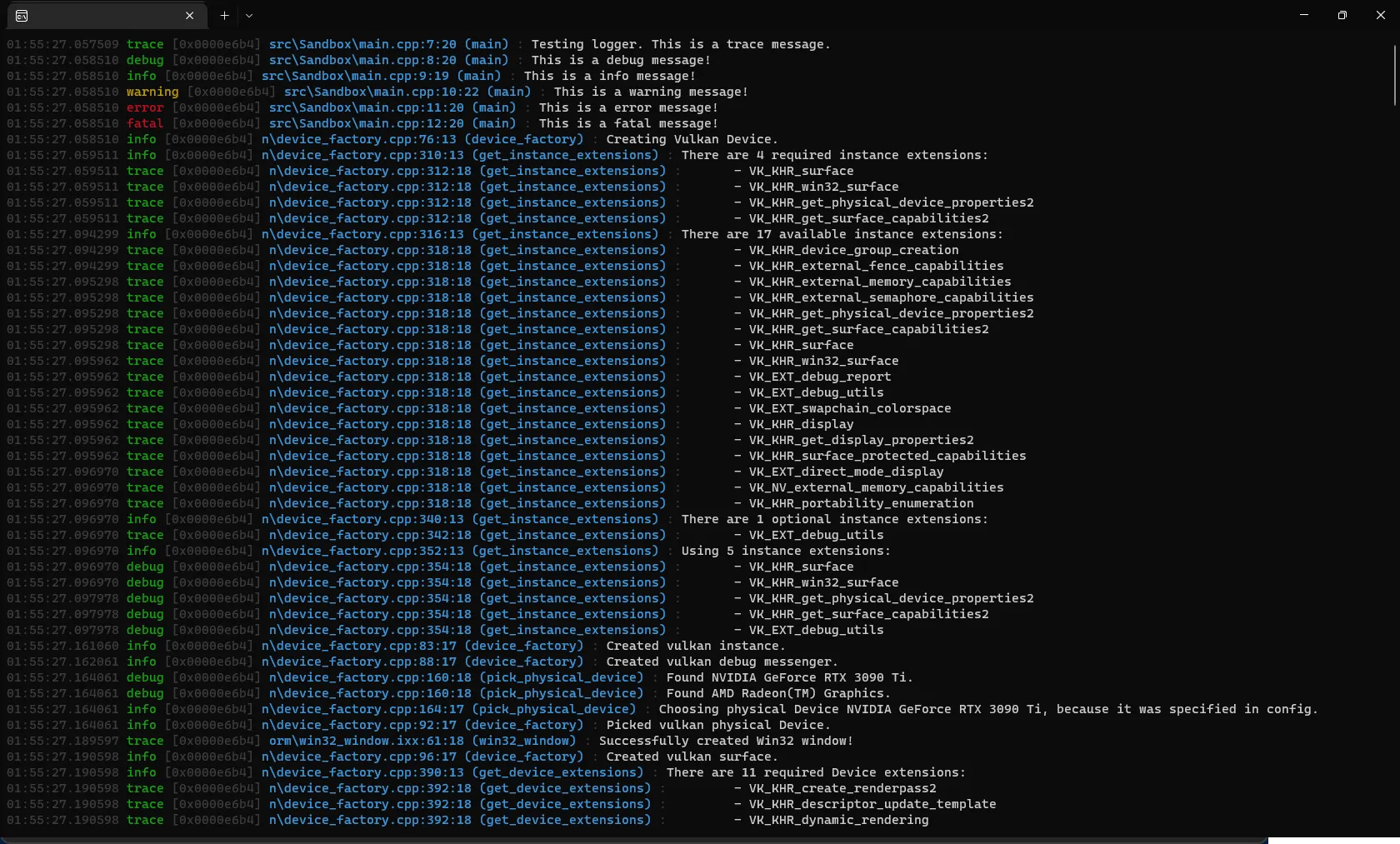
We want our output to look something like this:
First, we define a helper: coloring_expression wraps any formatter expression in ANSI escape
codes . We define an enum for the colors we use and a lookup table that maps each to its escape
sequence:
| Enum | Escape code | Effect |
|---|---|---|
kBlue | \033[34m | Blue text |
kCyan | \033[36m | Cyan text |
kFaint | \033[2;90m | Faint gray text |
kGreen | \033[32m | Green text |
kMagenta | \033[35m | Magenta text |
kRed | \033[31m | Red text |
kYellow | \033[33m | Yellow text |
The function emits the escape code before the formatted content and resets with \033[0;10m after:
enum Color { kBlue, kCyan, kFaint, kGreen, kMagenta, kRed, kYellow };
auto coloring_expression(auto fmt, Color color)
{
namespace expr = boost::log::expressions;
return expr::wrap_formatter(
[fmt, color](boost::log::record_view const& rec,
boost::log::formatting_ostream& stream) {
const static auto lookup = std::array {
"\033[34m", "\033[36m", "\033[2;90m",
"\033[32m", "\033[35m", "\033[31m", "\033[33m",
};
stream << lookup[color];
fmt(rec, stream);
stream << "\033[0;10m";
});
}Another helper truncates file paths from the front (so you see evice_factory.cpp:42 instead of a full absolute path):
std::string_view last_n_backward(const boost::log::value_ref<std::string>& value_ref, std::size_t n)
{
if (value_ref) {
auto& string = value_ref.get();
if (string.size() <= n) return string;
return { string.data() + string.size() - n, n };
}
return "";
}Now we compose the formatter. This is Boost.Log’s lambda-style formatter, essentially an iostream on steroids:
console_sink->set_formatter(expr::stream
<< coloring_expression(
expr::stream << expr::format_date_time<boost::posix_time::ptime>(
"TimeStamp", "%H:%M:%S.%f"),
kFaint)
<< " "
<< expr::if_(expr::is_in_range(severity,
LogLevel::trace, LogLevel::warning)) [
expr::stream << coloring_expression(
expr::stream << std::setw(7) << severity, kGreen)
].else_[
expr::stream << expr::if_(expr::is_in_range(severity,
LogLevel::warning, LogLevel::error)) [
expr::stream << coloring_expression(
expr::stream << std::setw(7) << severity, kYellow)
].else_[
expr::stream << coloring_expression(
expr::stream << std::setw(7) << severity, kRed)
]
]
<< " "
<< coloring_expression(
expr::stream << "[" << expr::attr<attr::current_thread_id::value_type>("ThreadID") << "] ",
kFaint)
<< coloring_expression(
expr::stream << "[" << std::setw(12) << std::left
<< expr::attr<std::string>("Channel") << "] ",
kMagenta)
<< coloring_expression(
expr::stream
<< boost::phoenix::bind(&last_n_backward, expr::attr<std::string>("File"), 20)
<< ':' << expr::attr<std::uint_least32_t>("Line") << ':' << expr::attr<std::uint_least32_t>("Column"),
kCyan)
<< coloring_expression(expr::stream << " : ", kFaint)
<< expr::smessage
<< expr::auto_newline
);We rely on each record (through the attribute sets we discussed in the introduction) to have the following pieces of information:
- Timestamp in
HH:MM:SS.ffffffformat, faintly colored so it doesn’t dominate. - Severity padded to 7 characters, color-coded: green for trace through info, yellow for warning, red for error and fatal.
- Thread ID in brackets, faint.
- Channel in brackets, left-aligned to 12 characters, in magenta.
- Source location: last 20 characters of the file name, line, and column in cyan. Note that the attribute type must be
std::uint_least32_tto match whatstd::source_location::line()andcolumn()return. Boost.Log’s attribute lookup is type-exact, so a mismatch (e.g.int) would silently produce empty output. - The message itself, with automatic newlines.
Finally, we register the sink and add common attributes. add_common_attributes() registers four global attributes: LineID (a record counter, unsigned int), TimeStamp (local clock, boost::posix_time::ptime), ProcessID (current process identifier), and — in multithreaded builds — ThreadID (current thread identifier). Our formatter already uses TimeStamp and ThreadID:
boost::log::core::get()->add_sink(console_sink);
boost::log::add_common_attributes();
return lg;
}Implementing _log
The _log function retrieves the global logger and writes the message. As discussed earlier, each record should have information on the source
location. For that, Boost.Log provides
add_value , a stream manipulator that attaches attributes to
the individual log record inside the BOOST_LOG_SEV expression.
void _log(LogLevel level, std::string_view message,
const std::source_location& loc)
{
auto& logger = gLogger::get();
BOOST_LOG_SEV(logger, level)
<< boost::log::add_value("File", std::string(loc.file_name()))
<< boost::log::add_value("Line", loc.line())
<< boost::log::add_value("Column", loc.column())
<< boost::log::add_value("Function", std::string(loc.function_name()))
<< message;
}At this point, engine::log_info("hello {}", "world") works end to end. The CTAD struct formats the message, captures the source location, and calls
_log, which attaches everything to the record and writes it to the global logger.
Per-subsystem logging with channels
The global logger is fine for small programs, but a game engine has many subsystems: the renderer, audio, physics, networking, and so on. When something goes wrong you want to quickly find all messages from a specific subsystem. This is what channels are for. Our formatter already prints the channel in magenta brackets, but right now every message goes through the “General” channel.
Wouldn’t it be nice to write this?
engine::Logger renderer_log{"Renderer"};
engine::log_info(renderer_log, "Created {} framebuffers", count);
engine::Logger audio_log{"Audio"};
engine::log_debug(audio_log, "Loaded {} samples", sample_count);The output for these would show [Renderer ] and [Audio ] in the channel column, making it easy to visually scan or grep for a specific
subsystem.
The Logger class
To support this, we need a Logger class that carries its own channel name and its own Boost.Log logger instance. Here’s where it gets interesting:
the Logger class needs to own a boost::log::sources::severity_channel_logger_mt, which is a complex template type pulling in a lot of Boost
internals. If we put it directly in the class definition in our .ixx file, all those types become part of the module’s exported interface.
The solution is the Pointer-to-Implementation
(PIMPL) idiom. Instead of putting the class’s data members directly in the module interface, we
forward-declare a private struct Impl and store a std::unique_ptr to it. The actual definition of Impl (that contains all the boost types) only
appears in the .cpp file. This way, the module interface only needs to know that Impl exists, not what’s inside it.
An additional benefit is that it keeps the module’s export surface small, we avoid recompilation cascades. Almost every module in the engine imports
engine.log. Any change in the *.ixx would force a rebuild of the entire project. With PIMPL, only logger.cpp recompiles.
This also helps with DLL/shared library compatibility: since the class layout doesn’t change when the implementation changes, you can update the library without recompiling all consumers 3 .
class Logger {
struct Impl;
std::unique_ptr<Impl> impl_;
public:
explicit Logger(std::string_view channel);
Logger(); // Default: "General" channel
Logger(const Logger&) = delete;
Logger& operator=(const Logger&) = delete;
Logger(Logger&&) noexcept;
Logger& operator=(Logger&&) noexcept;
~Logger();
void log(LogLevel level, std::string_view message,
const std::source_location& loc = std::source_location::current()) const;
};Note that PIMPL requires us to declare the destructor, move constructor, and move assignment operator in the .ixx and = default them in the
.cpp because std::unique_ptr<Impl> needs to see the full definition of Impl to generate them.
Extending the CTAD helpers
Now we add a second overload to each CTAD struct for the Logger& case:
export template <typename... Ts>
struct log_info {
// Log with a specific Logger instance (channeled)
inline log_info(const Logger& logger, std::format_string<Ts...> fmt, Ts&&... ts,
const std::source_location& loc = std::source_location::current())
{
logger.log(LogLevel::info, std::format(fmt, std::forward<Ts>(ts)...), loc);
}
// Log with the global logger
inline log_info(std::format_string<Ts...> fmt, Ts&&... ts,
const std::source_location& loc = std::source_location::current())
{
::engine::_log(LogLevel::info, std::format(fmt, std::forward<Ts>(ts)...), loc);
}
};
export template <typename... Ts>
log_info(const Logger&, std::format_string<Ts...>, Ts&&...) -> log_info<Ts...>;
export template <typename... Ts>
log_info(std::format_string<Ts...>, Ts&&...) -> log_info<Ts...>;We now have one additional deduction guide, one per overload. The compiler picks the right constructor based on whether
the first argument is a Logger or a format string.
The Impl definition
In logger.cpp, we define the Impl struct. It wraps a per-channel logger with its own source location attributes:
struct Logger::Impl {
ChannelLogger logger;
explicit Impl(std::string_view channel)
: logger(boost::log::keywords::channel = std::string(channel))
{}
};Logger::log works just like the global _log, using add_value for thread-safe per-record attributes:
void Logger::log(LogLevel level, std::string_view message,
const std::source_location& loc) const
{
BOOST_LOG_SEV(impl_->logger, level)
<< boost::log::add_value("File", std::string(loc.file_name()))
<< boost::log::add_value("Line", loc.line())
<< boost::log::add_value("Column", loc.column())
<< boost::log::add_value("Function", std::string(loc.function_name()))
<< message;
}Per-channel filtering
Now that we have channels, it would be useful to control verbosity per channel at runtime. Maybe you want trace-level output from the renderer while debugging a graphics issue, but only errors from the audio system.
Boost.Log has a built-in
channel_severity_filter
for exactly this use case. It maps channel names to minimum severity thresholds. It’s templated on the channel and severity types, so it works with
our LogLevel enum directly — it just needs operator>= (which we need to implement for our enum class).
namespace expr = boost::log::expressions;
// severity and channel keywords defined earlier in the file
auto min_severity = expr::channel_severity_filter(channel, severity);
min_severity["Renderer"] = LogLevel::trace;
min_severity["Audio"] = LogLevel::error;
min_severity["Physics"] = LogLevel::none; // none = 100, so nothing passes >= 100
boost::log::core::get()->set_filter(min_severity || severity >= LogLevel::info);The filter checks each log record’s channel against the map and compares the severity to the configured threshold using >=. This is also
why LogLevel::none (value 100) works as a mute: no real severity level will ever be >= 100, so every record from that channel gets rejected.
Channels not in the map use whatever was passed to set_default.
Summary
We started from the API we wanted — engine::log_info("value={}", 42) with no Boost types visible — and worked backwards. CTAD structs solve the
variadic template / default source_location conflict, a module-internal _log function keeps all Boost.Log machinery in the .cpp, and a global
logger with ANSI-colored formatters and async sinks handles the actual output. From there, we added a Logger class with PIMPL for per-subsystem
channels and Boost.Log’s built-in channel_severity_filter for runtime verbosity control.
In the next article, we’re going to look at the high-level architecture of our renderer.
Footnotes
-
Remember, we are creating a framework so we provide components like logging “automagically”. ↩
-
Note that at the time of writing Apache Chainsaw’s Binary Distribution is only compatible with Java 8. Yes, I’m serious. ↩
-
Care must be taken with templated types like
std::unique_ptracross DLL boundaries, since their layout depends on the standard library implementation and compiler settings. In practice this is fine when both sides are built with the same toolchain. ↩